Tabulated Data Inference
Overview
The library that I wrote utilizes a parser combinator (specifically, mpc) to automatically identify the data types from tabulated data. Its primary advantages are its ability to automatically identify:
- The delimiter (data delimited with
,,;,\t, and - Date/time/datetime strings of (nearly) any format with no prior knowledge about the format.
Motivation and Problem Definition
For my senior capstone engineering project at Olin, I was working with air quality instruments such as the Aerodyne ACSM and the Brechtel SEMS. In writing software for real-time monitoring of these instruments and analysis of the data they generated, I noticed that every instrument had a different way of reporting data. Every datetime format was different; some data files were .dat files with tab-delimited data preceded by several lines of metadata, whereas others were standard .csv files; and the data types covered everything from logical values to bit strings to floating point numbers using scientific notation. As a result, a lot of the code I wrote either had to be instrument-dependent or reference a complex configuration file that specified the ways in which each instrument encoded its data.
As a project in my entrepreneurship class, I decided to investigate the feasibility of and make prototypes for a client + cloud software product that would, among other things, be able to automatically ingest any scientific instrument’s data and make sense of it. To that end, I wrote this library to parse tabulated data files and identify and extract information about each column of data.
Solution
Being able to identify the delimiter and column names even with metadata preceding the tabulated data turned out to be relatively straightforward problem to solve, but the real challenge came in distinguishing a date/time/datetime string of any standard format from an arbitrary string (and in some cases, integers). To solve this problem, I used a parser combinator and defined a grammar that accepts strings representing:
- Boolean values
- Bit strings
- Datetime strings
- Time strings
- Date strings
- Integers
- Floating point numbers (in decimal notation)
- Floating point numbers (in scientific notation)
Using the Boost library’s date and time string formatting rules as a reference, this table enumerates a (non-exhaustive) selection of the various date/time/datetime formats that can be classified by the library:
| Boost Format | Example | Classification |
|---|---|---|
%m-%d-%y |
04-02-2022 |
Date string |
%d%m%y |
181021 |
Date string |
%m-%d-%y |
04-02-22 |
Date string |
%Y-%m-%d (ISO extended) |
2022-04-02 |
Date string |
%Y%m%d (ISO format, date only) |
20220402 |
Date string |
N/A (extra character over %m-%d-%y) |
12-34-56789 |
Arbitrary string |
| N/A (expect 12 hr time when PM is used) | 13-34-2022 PM |
Arbitrary string |
%H:%M:%S%F %p |
10:03:22.0023 PM |
Time string |
%H:%M:%S%F %p %ZP |
13:03:22.0023 PM MST-07 |
Time string |
%H%M%S%F%q (ISO format, time only) |
131211-0700 |
Time string |
%Y-%b-%d %H:%M:%S%F %ZP (boost default input) |
2005-Oct-15 13:12:11 MST-07 |
Datetime string |
%Y%m%dT%H%M%S%F%q (ISO format) |
20051015T131211-0700 |
Datetime string |
N/A (%m-%d-%y %H:%M sans leading zeros) |
2/9/2022 0:16 |
Datetime string |
Example
The most challenging data files I used as test cases were the ones produced by the Brechtel SEMS. They include tab-delimited data with several lines of metadata preceding the actual data and, for some reason, a blank line in-between the row of column names and the first row. They also include a variety of data types to be parsed, including date strings, time strings, floating points, and logical values. For example, this file is used for the unit tests:
... (preceding lines removed for brevity)
#
#Transformations/Corrections
#---------------------------
#Desmearing: N = N0 * exp( -t / tau )
#Tau: 0.250
#CPC Counting Efficiency: nu = 1 - (C0 / (1 + exp((Dp - C1)/C2)))
#C0 = 1.025000
#C1 = 7.929000
#C2 = 0.845000
#
#=================================================
#StartDate StartTime EndDate EndTime ScanDirection Sheath_Press Sheath_Temp Sheath_Avg Sheath_Sdev Sheath_RH ColSamp_Avg ColSamp_Sdev ColSamp_RH ColSamp_Temp CPC_A_FlwAvg CPC_A_Sdev Sat_Temp Cond_Temp SEMS_Errors MCPC_Errors Impactr_Press Bin_Dia1 Bin_Dia2 Bin_Dia3 Bin_Dia4 Bin_Dia5 Bin_Dia6 Bin_Dia7 Bin_Dia8 Bin_Dia9 Bin_Dia10 Bin_Dia11 Bin_Dia12 Bin_Dia13 Bin_Dia14 Bin_Dia15 Bin_Dia16 Bin_Dia17 Bin_Dia18 Bin_Dia19 Bin_Dia20 Bin_Dia21 Bin_Dia22 Bin_Dia23 Bin_Dia24 Bin_Dia25 Bin_Dia26 Bin_Dia27 Bin_Dia28 Bin_Dia29 Bin_Dia30 Bin_Conc1 Bin_Conc2 Bin_Conc3 Bin_Conc4 Bin_Conc5 Bin_Conc6 Bin_Conc7 Bin_Conc8 Bin_Conc9 Bin_Conc10 Bin_Conc11 Bin_Conc12 Bin_Conc13 Bin_Conc14 Bin_Conc15 Bin_Conc16 Bin_Conc17 Bin_Conc18 Bin_Conc19 Bin_Conc20 Bin_Conc21 Bin_Conc22 Bin_Conc23 Bin_Conc24 Bin_Conc25 Bin_Conc26 Bin_Conc27 Bin_Conc28 Bin_Conc29 Bin_Conc30
181021 16:02:53 181021 16:03:25 1 1008 293.0 5.00 0.006 41 0.332 0.004 44 293.8 0.361 0.000 318.1 293.0 0 0 1.3 5.36 6.17 7.09 8.16 9.39 10.80 12.43 14.32 16.50 19.02 21.93 25.31 29.24 33.80 39.12 45.34 52.63 61.22 71.36 83.41 97.82 115.16 136.21 161.97 193.82 233.60 283.78 347.64 429.57 535.30 0.00 0.00 63.25 142.38 265.95 406.84 861.64 1936.16 2997.35 5231.52 6265.10 8117.19 10347.52 11147.31 13780.78 14020.80 13887.50 11887.87 8326.53 5639.37 2365.64 1078.11 564.21 367.12 359.97 126.26 39.08 19.28 4.18 36.05
181021 16:03:40 181021 16:04:10 0 1008 293.0 5.00 0.006 41 0.330 0.003 44 293.8 0.361 0.000 318.1 293.0 0 0 1.3 5.36 6.17 7.09 8.16 9.39 10.80 12.43 14.32 16.50 19.02 21.93 25.31 29.24 33.80 39.12 45.34 52.63 61.22 71.36 83.41 97.82 115.16 136.21 161.97 193.82 233.60 283.78 347.64 429.57 535.30 0.00 0.00 19.99 47.64 98.55 212.24 277.82 290.42 164.93 345.82 503.09 623.19 844.23 893.09 710.15 958.30 949.33 472.34 715.62 323.65 341.05 341.94 414.09 211.14 312.16 184.17 117.04 135.98 11.55 1.41
181021 16:04:25 181021 16:04:56 1 1008 293.0 5.00 0.006 41 0.330 0.000 43 293.9 0.361 0.002 318.1 293.0 0 0 1.3 5.36 6.17 7.09 8.16 9.39 10.80 12.44 14.32 16.50 19.02 21.93 25.31 29.24 33.80 39.12 45.34 52.64 61.22 71.36 83.41 97.82 115.16 136.20 161.97 193.81 233.59 283.75 347.61 429.52 535.23 0.00 0.00 18.67 51.15 117.25 264.05 380.46 294.87 334.65 449.28 716.25 585.34 774.78 1146.46 1148.51 1019.48 754.39 642.54 540.29 510.22 760.03 529.62 391.75 303.28 348.90 238.12 143.86 10.56 1.66 0.11
181021 16:05:10 181021 16:05:41 0 1008 293.1 5.00 0.009 42 0.330 0.000 42 294.0 0.360 0.001 318.1 293.0 0 0 1.3 5.36 6.17 7.09 8.16 9.39 10.80 12.44 14.32 16.50 19.02 21.93 25.31 29.24 33.80 39.12 45.34 52.64 61.22 71.36 83.41 97.82 115.16 136.20 161.96 193.80 233.57 283.73 347.57 429.46 535.15 0.00 0.00 1.12 3.77 10.65 29.93 90.24 274.72 328.70 376.08 442.66 954.42 706.54 732.08 704.70 1087.59 836.92 784.19 690.07 629.20 451.05 257.94 378.84 415.27 267.83 169.37 47.19 37.79 3.07 0.34
Using just three functions from the library, each field from the data file and its classification can be identified. An excerpt from the example script shows how this works:
cout << "Finding delimiter..." << endl;
auto delimRet = getDelim(thisFileLines);
cout << "Finding fields..." << endl;
vector<vector<string>> fieldRet;
int consistentFields = getFields(thisFileLines, get<0>(delimRet), fieldRet, get<1>(delimRet));
cout << "Classifying fields..." << endl;
vector<tuple<string, FieldCls>> classificationRet;
classifyColumns(fieldRet, classificationRet, parser);
cout << "Data insights for " << fileTargets.at(fileIdx) << ":" << endl;
for (auto classification: classificationRet) {
cout << " - " << get<0>(classification) << " (" << FieldClsCorrespondingNames[get<1>(classification)] << ")"
<< endl;
}
This prints the following for the above example file:
Finding delimiter...
Finding fields...
Classifying fields...
Data insights for tests/test_targets/long_SEMS.dat:
- #StartDate (date)
- StartTime (time)
- EndDate (date)
- EndTime (time)
- ScanDirection (logical)
- Sheath_Press (int)
- Sheath_Temp (float_dec) // Decimal floating point
- ... (remaining lines removed for brevity)
Future Work
Because of the way the language grammar is structured, a prime opportunity for a new feature would be the derivation of the date/time string format from the abstract syntax tree generated for a given input. For example, using a function from the parser combinator library’s that prints a representation of the abstract syntax tree, we can see the tree generated for the input 2005-Oct-15 13:12:11 MST-07:
>
regex
datetime|>
date|>
year_4_digit|regex:1:1 '2005'
char:1:5 '-'
month_b|regex:1:6 'Oct'
char:1:9 '-'
day|regex:1:10 '15'
char:1:12 ' '
time|>
hour_24|regex:1:13 '13'
char:1:15 ':'
minute|regex:1:16 '12'
char:1:18 ':'
second|regex:1:19 '11'
char:1:21 ' '
tz_ZP|regex:1:22 'MST-07'
regex
The tz_ZP tag, for instance, refers to the %ZP flag that is used for printing time zones using the Boost library in the MST-07 format. More opportunities for improving the library are listed in the repository README.
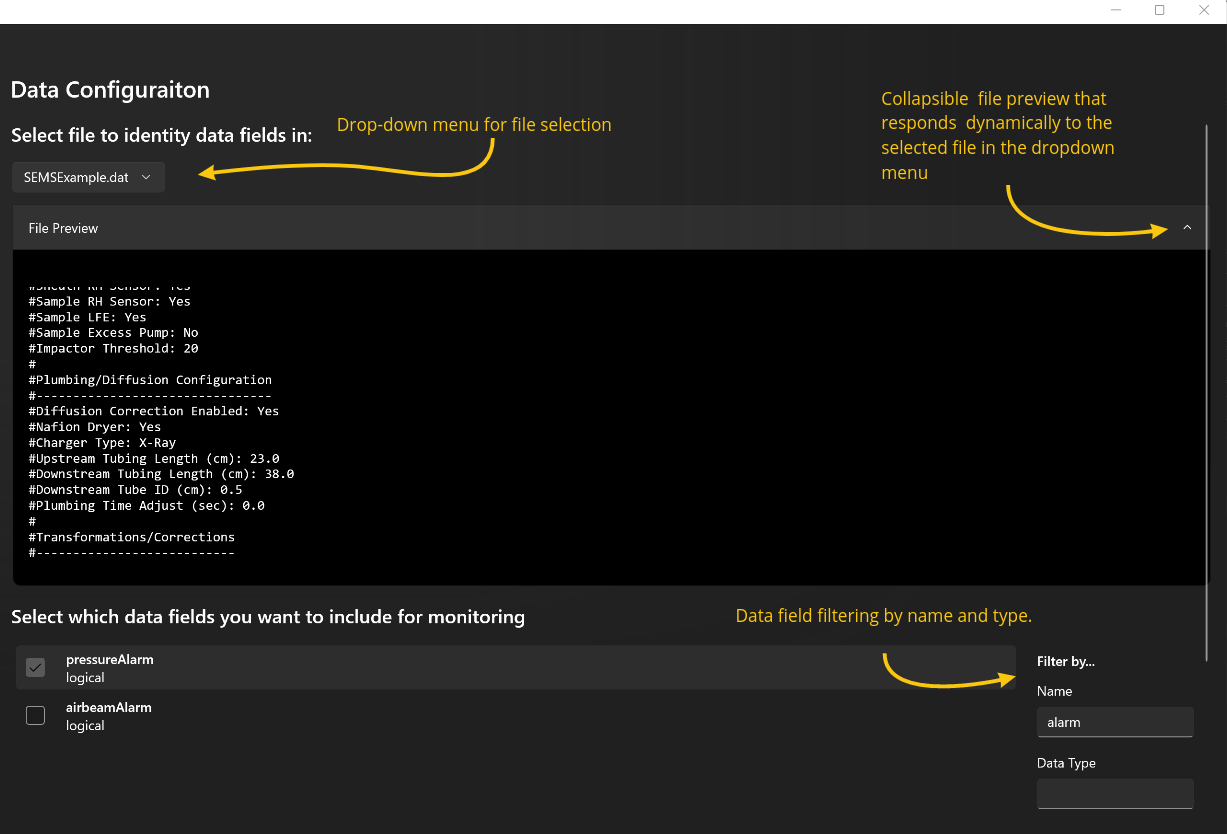
Additionally, because, as mentioned in the motivation section, I worked on this as part of a project to prototype and make a business case for a product, I also made a functional prototype of a desktop client that would make use of this library’s capabilities. I made this GUI in C# using Microsoft’s WinUI 3 platform for native Windows application development. This application can serve as a springboard for future work in integrating the library into useful user-facing products.